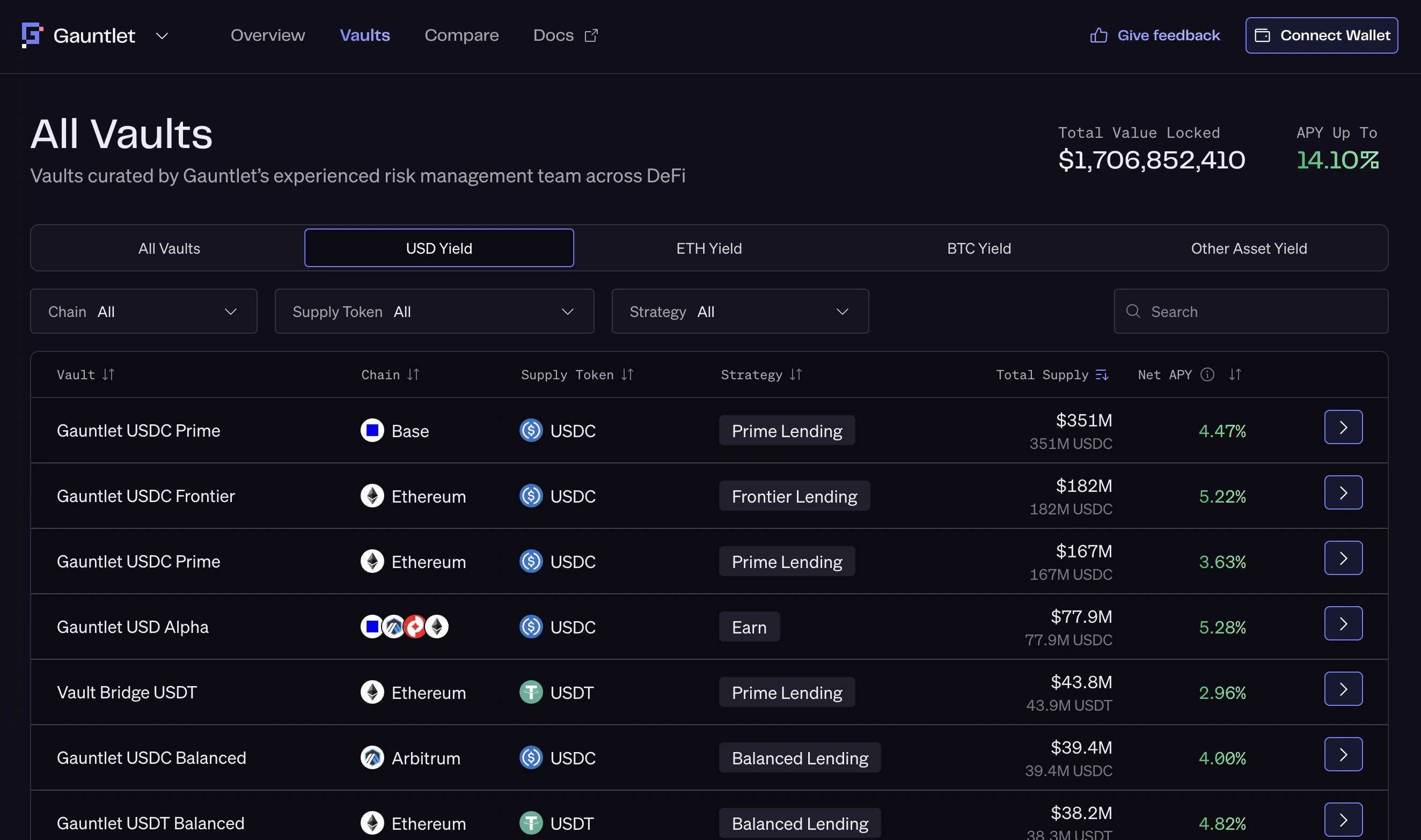
The Challenge: Fragmented, High-Maintenance Yield Data
Gauntlet’s models depend on high-quality onchain data, but aggregating yield data at scale presents compounding challenges:- Data fragmentation: Yield mechanisms differ widely across protocols, making standardized comparisons difficult without normalization for metrics such as supply/borrow APYs, staking rewards, and real-world asset returns.
- Maintenance burden: In-house indexers require constant updates as protocols evolve, consuming engineering resources that could go toward modeling.
- Cross-chain complexity: Coverage across multiple L1s and L2s multiplies the surface area to monitor, and errors at the data layer propagate into research outputs.
The Solution: A Single API for Normalized Yield Data
By integrating vaults.fyi, Gauntlet can:- Access normalized APY data across protocols and blockchain networks through a single interface.
- Pull historical yield trends to analyze volatility, time-based behavior, and protocol-specific risk.
- Incorporate live and historical vault data into quantitative models without building custom pipelines per protocol.
- Eliminate maintenance overhead as protocols update, upgrade, or launch new products.
Outcome
vaults.fyi serves as a data partner supporting Gauntlet’s research across DeFi. As Gauntlet pushes the frontier of onchain economic modeling, normalized yield data from vaults.fyi feeds directly into the risk models that protect billions in digital assets.Integrating DeFi yield data into your research stack? Get API access to explore the historical and market data endpoints Gauntlet uses.